Stream Processing¶
overview¶
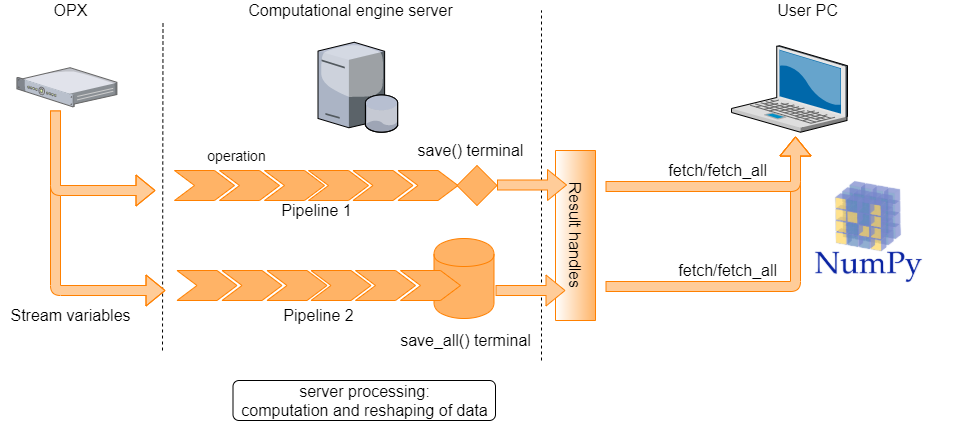
When saving data from a QUA program, it is first saved on the OPX on-board memory. From there, it’s transferred to the server and eventually to the user PC. Stream processing provides the capability to process data as it is being transferred to the QM server. This both reduces the amount of data that has to be saved on the user PC, as well as the post-processing computation time.
Consider, as a simple example, a case where we would like to characterize the success rate of preparing a bit in the \(|1 \rangle\) state. We want to play the pulse, read-out the qubit state and decide whether it is a \(|1\rangle\) or a \(|0\rangle\). We then repeat this some large number of times, say \(1 \times 10^5\). Collecting the results of all \(10^5\) experiments is not so interesting, we can instead only collect the final average of the set of experiments or how this average develops as data is accumulated.
A running average is a particularly simple example, but many other manipulations are possible. These allow for both complex operations and data reshaping to be performed on server, in parallel to OPX experimental runs.
basic syntax and example¶
To use the server processing feature, a stream must be defined. A stream consists of a stream variable, a pipeline and a terminal. The processed stream items can be accessed on the client PC, where they are referred to as results by creating result handles on the client PC. In what follows, we introduce each of these components and explain how they are used.
To initiate a stream, we declare a stream variable, using the following syntax inside a QUA program:
my_stream = declare_stream()
To pass a variable to a stream, we use the save() statement or the measure() statement.
This creates a data transfer path through which stream items are processed and then saved to either
a permanent or overriding storage (see Glossary for more details).
To illustrate how pipelines and terminals are created and used, we show below a full QUA program which saves data to a stream, manipulates it and stores the results to terminals:
with program() as prog:
my_stream1 = declare_stream(adc_trace=True)
my_stream2 = declare_stream()
a = declare(fixed)
assign(a, 0.3)
save(a, my_stream2)
measure('my_pulse', 'qe', my_stream1)
with stream_processing():
my_stream1.input1().with_timestamps().save('adc_results')
my_stream2.save_all('a_results')
Here two streams are created. The first, my_stream1, is used to stream raw ADC samples.
The second, my_stream2, is used to stream the value of the QUA variable a.
The pipelines and terminals are defined under the with stream_processing() context. Pipelines initiate with a
stream variable and terminate with a save() or save_all()
function, which acts as a terminal. In this example the pipelines are
simple: The first selects only the data from analog input1 and adds timestamps to it. The second is immediately terminated.
The terminal used for the pipeline initiated with my_stream1 is a Save terminal.
This is a memoryless terminal that only holds only the last value transferred - this can result in data loss if data
is not fetched quickly enough from the client PC. The terminal is given the tag 'adc_results', which can later
referenced using a result handle.
The terminal for my_stream2 is a save_all terminal which does store all the results (up to a memory
limitation, see Server PC storage and data limitations). The tag for this terminal is 'a_results'.
Finally, we note that by setting adc_trace=True we specify that data should be grouped into individual ADC
traces and not passed on a sample-by-sample manner.
To access the results on the client PC side, we create a Result handle. This allows us to retrieve (“fetch”) the stream items on the client PC side, or to perform other query or storage operations on it. To continue our example:
job = qm.execute(prog)
res = job.result_handles
my_stream_res = res.adc_results.fetch_all()['value']
This example collects all results which were contained in the stream using the
fetch_all() method.
Alternatively, we can only get the most recent result by calling the fetch() method.
Note that both these method are called on a result handle. This structure and its usage are described below.
Note
it is still possible to use the syntax from previous versions for creating a stream that is only terminated
using save_all(). The following are equivalent:
with program() as prog:
my_stream = declare_stream()
a = declare(fixed)
assign(a, 0.3)
save(a, my_stream)
with stream_processing():
my_stream.save_all('a_results')
and
with program() as prog:
a = declare(fixed)
assign(a, 0.3)
save(a, 'a_results')
Results handles¶
The stream items stored in the save/save all terminals on the server PC can be fetched to the client PC using the
results_handles property of the qm.QmJob object.
The fields of the result_handles property contain references to the stream terminals, and their names are the
same as the tags given to the terminals.
A handle to a specific terminal with tag "my_result", for example, is accessed with
my_result = job.results_handles.get("my_result").
A shorthand notation for this is my_result = job.results_handles.my_result.
We can query both the state of a single result handle or that of the collection of all results handles.
For example, one can query the processing state using the is_processing() method,
or the wait_for_all_values() method to suspend python execution until either a timeout has occurred or
saving has completed.
In case the handle references results from a save terminal, we can also wait for a specific number of results
to arrive using the wait_for_values(count) method.
The number of stream items referenced by a specific result handle can be obtained by calling count_so_far()
on that handle, or equivalently by calling len(my_result).
Saving results in numpy format to a local variable is done using the fetch and fetch_all
methods as specified below.
We can also save results to the file system by calling save_to_store(path).
fetch and fetch_all¶
To transfer the results from the server PC to the client PC, fetch and fetch_all commands are called on a result handle, for example:
my_stream_res=res.my_stream.fetch_all()
where my_stream is the tag result tag given to the save/save_all terminal.
fetch collects the most recent result in the stream and fetch_all collects all saved data. In the case a save terminal is used, fetch all is equivalent to fetch.
It is also possible to collect only a portion of the collected data by passing fetch a slice object. For example, say your result stream contains [0,1,2,3,4,5,6,7,8,9]. fetch(0) returns 0, fetch(4) returns 4 and fetch(slice(2,5) returns [2,3,4,5]. Any valid python slice object can be used.
combining streams using the zip operator¶
Streams can be zipped together into tuples of results. This is similar to creating a buffer but combines data from two seperate streams rather than reshaping a single one. In this case, the zipped resulting stream will have a shape dictated by the number of zipped tuples. Each element of this tuple is a named field value_i where i the named field number (the index of the zipped stream).
A_stream.zip(B_stream).save_all("zipped_tuple")
...
zipped = job.result_handles.zipped_tuple.fetch_all()
zipped has a shaped based on the number of items n. It has two named fields: value_0 and value_1.
flat data structure option¶
The data structure returned by calling fetch_all is a numpy structured array. In simple cases, where buffering is not used, the shape of this array is exactly given by the number of saved items. If time stamps are also included, there is a single column of values and a second column with timestamps. If, however the data is buffered or manipulated in some way, the number of items in the output array will be the number of filled (or partially filled) buffers. For example, concider the following buffered stream
stream.buffer(10).buffer(5).save_all()
If we had 300 items entering the steam, the shape of the output stream numpy array is: 6 (10*5*6 = 300). Each numpy array item has shape 10 X 6, but because the inner dimensions are “hidden” this is not indexable in the way you might expect.
To modify this behaviour, an option to “flatten” the result array has been added. This is called by passing the following parameter to fetch_all:
job.result_handles.samples.fetch_all(flat_struct=True)
In this case, the result shape will have the shape (6,5,10) and indexing can be performed as is usual in numpy array.
If the flat_struct flag is used on zipped streams, each named field will have a shape as described for a single stream.
Server PC storage and data limitations¶
A save_all terminal will store in the all of the stream items created during the execution
of a QUA program as results in the permanent memory of the server PC.
The permanent memory of the server PC is large but not unlimited, and therefore it is possible in some cases
to create more results than can be stored at the server PC.
The server PC permanent memory can store up to 100GB of result data without danger of data-loss.
Warning
If more than 100GB are stored in the permanent memory, the data may be erased after a short time to ensure the permanent storage is not overfilled. To ensure that job results are not erased, always make sure that no more than 100GB of data are generated by the QUA program without being fetched.
The results will not be immediately erased from the server once they are fetched.
To clear the permanent storage and ensure that all of the 100GB are available, use the
qm.QuantumMachineManager.clear_all_job_results() method.
Data restructuring with buffer()¶
The buffer method allows reshaping of the incoming stream items. For example
my_stream.buffer(2).save_all('output_name')
Will result in a stream of number pairs. And
my_stream.buffer(2,2).save('output_name')
Will result in a stream of 2 by 2 matrices. This is useful inside a doubly nested for loop as we can loop over a pair of independent variables and save the resulting dependent variable with the correct structure. We can then perform additional processing. For example, we can perform a running average over the resulting matrix in the following way:
my_stream.buffer(2,2).average().save()
This allows us to collect the the resulting matrix and observe how the average evolved with the subsequent runs in real time.
Data loss notification¶
When collecting results from a stream, the system can usually estimate how much data is expected to be received.
For example, if the measure command plays a pulse with a duration of 1000 samples, we expect to collect
an output of that length. In cases where the expected amount of data does not match the received amount,
an error message will appear when the res.my_stream.fetch_all() or .fetch() commands are called.
It can also be manually checked by calling
res.my_stream.has_data_loss()
Glossary¶
- Stream Variable
A source (or start point) of a pipeline, receives values of QUA variables or raw input samples as input
- Save Terminal
An overriding named sink or (end point) of a pipeline that creates a result. Each new stream item received at this terminal, will override the previous. The result is a single item, the last one received in a stream
Warning
using a save terminal can result in data loss. It is to be used only in cases where data loss is acceptable, such as streaming plots.
- Save All Terminal
A named sink or end point of a pipeline that creates a result, which stores all the stream items in the pipeline. All stream items are appended to the result, complete history of the stream is preserved
- Pipeline
An ordered collection of operations that is performed on an input stream to return a processed version of the stream (output stream) In the context of stream processing, it is the collection of operations that can be performed starting from a stream variable and terminating in a “save terminal” or “save all terminal” node
- Stream
An ordered set of values that are being sent from a QUA program into a pipeline. A stream is set up when a QUA program is started and is torn down when it is finished.
- Stream item
A single discrete unit of data of a stream. Can be one of the following:
ICP result
Single input sample from the controller
An input trace vector (single measure statement)
It is possible to augment the timestamp to each item using withTimestamp
- Result
The last or accumulated stream items that are created by save or save_all terminals, respectively
- Result Handle
An object through which results can be fetched